
Resumes are full of rich, structured information—but extracting this data automatically can be a challenge. In this blog, we’ll walk through how to build a Resume Q&A system using:
- LlamaIndex
- OpenAI’s Embeddings + GPT models
- LlamaParse for intelligent document parsing
- Workflow-based orchestration with
llama_index.core.workflow
Let’s dive into how you can transform a static resume into an interactive queryable system.
Overview
We’ll build a pipeline that:
- Parses a resume PDF and extracts content as markdown.
- Embeds the parsed content into a vector index using OpenAI embeddings.
- Allows querying via GPT-4o-mini.
- Enables reusable workflows and tools for consistent resume analytics.
Prerequisites
Before you begin, make sure you have:
llama-indexllama-parseopenainest_asynciofor Jupyter support- OpenAI and LlamaParse API keys
Step 1: Document Ingestion with LlamaParse
We use LlamaParse to extract structured content (in markdown) from resumes:
documents = LlamaParse(
api_key=llama_cloud_api_key,
result_type="markdown",
system_prompt_append="Extract the content from the document and return it in markdown format."
).load_data("data/Fake_Resume.pdf")This outputs clean, semantically rich text, ready for downstream indexing.
Step 2: Build a Vector Index
Next, we embed the parsed content using OpenAI’s text-embedding-3-small and build a vector index:
index = VectorStoreIndex.from_documents(
documents,
embedding=OpenAIEmbedding(
api_key=openai_api_key,
model="text-embedding-3-small"
)
)
Step 3: Query Using GPT-4o-mini
We create a query engine that uses gpt-4o-mini as the backend LLM:
query_engine = index.as_query_engine(
llm=OpenAI(model="gpt-4o-mini"),
similarity_top_k=3
)
Now you can ask natural language questions like:
response = query_engine.query("What is the name of the person and their current job title?")
print(response)
Output:
The name of the person in the resume is Homer Simpson, and their current job title is Night Auditor.Step 4: Persist and Reload the Index
To avoid rebuilding the index every time, persist it to disk:
index.storage_context.persist(persist_dir="./storage")
Later, you can reload it using:
storage_context = StorageContext.from_defaults(persist_dir="./storage")
restored_index = load_index_from_storage(storage_context)
Step 5: Turn Q&A Into a Tool
You can create reusable tools with FunctionTool and invoke them via a FunctionCallingAgent:
def query_resume(query: str) -> str:
return str(query_engine.query(query))
resume_tool = FunctionTool.from_defaults(fn=query_resume)
agent = FunctionCallingAgent.from_tools(
tools=[resume_tool],
llm=llm,verbose=True,)
Chat with your resume:
response = agent.chat("How many years of experience does the applicant have?")
print(response)
Output:
> Running step 7f4678c6-35e6-406a-a468-a202c5ae760e. Step input: How many years of experience does the applicant has?
Added user message to memory: How many years of experience does the applicant has?
=== Calling Function ===
Calling function: query_resume with args: {"query": "years of experience"}
=== Function Output ===
The name of the person in the resume is Homer Simpson, and their current job title is Night Auditor.
> Running step 21ac778c-2bb1-404a-b70b-8773e97cfbef. Step input: None
=== Calling Function ===
Calling function: query_resume with args: {"query": "Homer Simpson's years of experience"}
=== Function Output ===
The name of the person in the resume is Homer Simpson, and their current job title is Night Auditor.
> Running step 325fcb29-9753-47c1-b62d-9a18fcb17d18. Step input: None
=== LLM Response ===
It seems that I wasn't able to retrieve the specific years of experience for the applicant, Homer Simpson. If you have more details or specific sections of the resume you'd like me to check, please let me know!
It seems that I wasn't able to retrieve the specific years of experience for the applicant, Homer Simpson. If you have more details or specific sections of the resume you'd like me to check, please let me know!Surprisingly, the fake resume which i have taken does does not have experience mentioned.Also the prints your are seeing twice because he have mentioned verbose.
Step 6: Create a Workflow
LlamaIndex provides a declarative workflow API. Here’s a two-step RAGWorkflow:
The rag workflow we have created using all the experiments we have done individually above. The same code has been leveraged to create the workflow.
Flow Diagram:
StartEvent(resume_file, query)
|
v
+--------------------+
| setup_workflow |
|--------------------|
| Check file exists|
| Load or build index |
| Persist if new |
| Create query engine|
+--------------------+
|
v
QueryEvent(query)class RAGWorkflow(Workflow):storage_dir = "./storage"
llm: OpenAI
query_engine = VectorStoreIndex
@step
async def setup_workflow(self, ctx: Context, ev: StartEvent) -> QueryEvent:
#Check if resume file is provided
if not ev.resume_file:
raise ValueError("Resume file is required to setup the workflow.")
# Initialize the LLM
self.llm = OpenAI(model="gpt-4o-mini")
#Load Index from Persistent Storage (if available)
if os.path.exists(self.storage_dir):
storage_context = StorageContext.from_defaults(persist_dir=self.storage_dir)
index = load_index_from_storage(storage_context)
else:
#parse and load your documents
documents = LlamaParse(
api_key=llama_cloud_api_key,
result_type="markdown",
system_prompt_append="Extract the resume content from the document and return it in markdown format."
).load_data(ev.resume_file)
#embed and Index the documents
index = VectorStoreIndex.from_documents(
documents,
embedding=OpenAIEmbedding(
model_name="text-embedding-3-small",
)
)
index.storage_context.persist(persist_dir=self.storage_dir)
# Create the query engine
self.query_engine = index.as_query_engine(
llm=self.llm,
similarity_top_k=3
)
#Emit the QueryEvent to be consumed by ask_question function
return QueryEvent(query=ev.query)
@step
async def ask_question(self, ctx: Context, ev: QueryEvent) -> StopEvent:
response = self.query_engine.query(ev.query)
return StopEvent(result=str(response))
Run the workflow:
w = RAGWorkflow(timeout=60, verbose=False)
result = await w.run(
resume_file="data/Fake_Resume.pdf",
query="What is the name of the person and what is their current job title?"
)
print(result)
Output:
Loading llama_index.core.storage.kvstore.simple_kvstore from ./storage/docstore.json.
Loading llama_index.core.storage.kvstore.simple_kvstore from ./storage/index_store.json.
The name of the person in the resume is Homer Simpson, and their current job title is Night Auditor.Visualize the Workflow
Generate a visualization of the workflow logic:
draw_all_possible_flows(w, filename="workflows/rag.html")
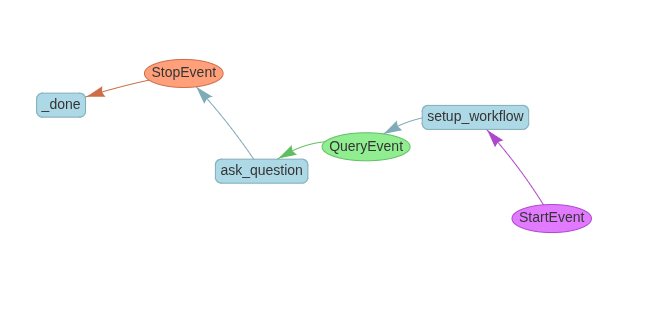
This is useful for documentation or debugging multi-step workflows.
Conclusion
With just a few lines of code and the power of LlamaIndex, OpenAI, and LlamaParse, we’ve built an intelligent resume analysis system. This setup can be extended to handle:
- Multiple resumes
- ATS (Applicant Tracking System) integrations
- Advanced analytics and scoring models
GitHub & Resources
- https://github.com/juggarnautss/Event_Driven_Agent_Doc_Workflow/blob/main/rag.ipynb
- LlamaIndex Docs
- LlamaParse
- OpenAI Embeddings
Author Profile

- AI | Amplifying Impact
- Talks about AI | GenAI | Machine Learning | Cloud | Kubernetes
Latest entries
 AgenticAIAugust 12, 2025Pipeline Companion – an AWS Strands Agent for Data Pipeline Monitoring
AgenticAIAugust 12, 2025Pipeline Companion – an AWS Strands Agent for Data Pipeline Monitoring AgenticAIAugust 7, 2025AWS Strand Agent – integration with Researcher MCP server
AgenticAIAugust 7, 2025AWS Strand Agent – integration with Researcher MCP server AgenticAIAugust 5, 2025Building an MCP Server Using FastMCP and arXiv
AgenticAIAugust 5, 2025Building an MCP Server Using FastMCP and arXiv AgenticAIAugust 3, 2025Building a Resume Question-Answering System Using LlamaIndex, OpenAI, and LlamaParse
AgenticAIAugust 3, 2025Building a Resume Question-Answering System Using LlamaIndex, OpenAI, and LlamaParse