
In this blog, we’ll explore how to design powerful and flexible multi-agent workflows using the llama_index framework. From basic sequential flows to advanced branching, loops, parallelism, and LLM-powered agents, you’ll learn how to model real-world software development pipelines as executable, traceable workflows.
Lets start with “Hello World” workflow
A very basic workflow class where it will receive the StartEvent and emits the StopEvent.
class AgentDocWorkflow(Workflow):
@step
async def my_step(self, ev: StartEvent) -> StopEvent:
"""
This is a sample step in the workflow.
"""
return StopEvent(result="Hello World")Instantiate and run it. Now instantiate the workflow and wait for the function to complete using await keyword.
basic_workflow = AgentDocWorkflow(timeout=10, verbose=False)
result = await basic_workflow.run()
print(result)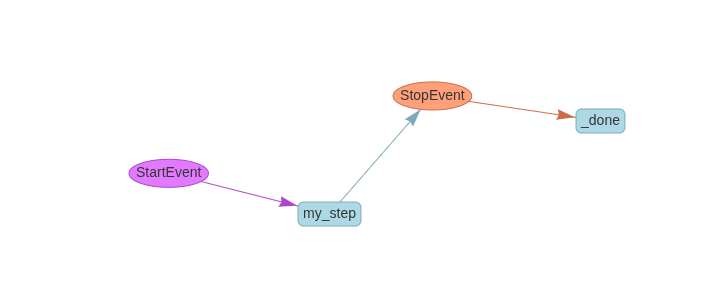
Sequential Multi-Step Workflow
Let’s build a linear sequence: developer → tester → deployer.
class DeveloperWorkflow(Workflow):
@step
async def developer(self, ev: StartEvent) -> Code:
return Code(code_output="Code completed successfully")
@step
async def tester(self, ev: Code) -> Test:
return Test(test_output="Test completed successfully")
@step
async def deployer(self, ev: Test) -> StopEvent:
return StopEvent(result="Deployment completed successfully")Visualization:
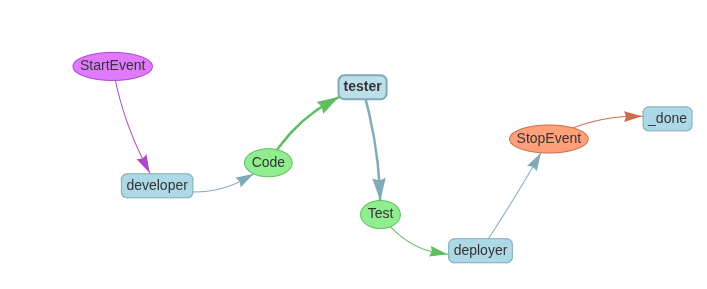
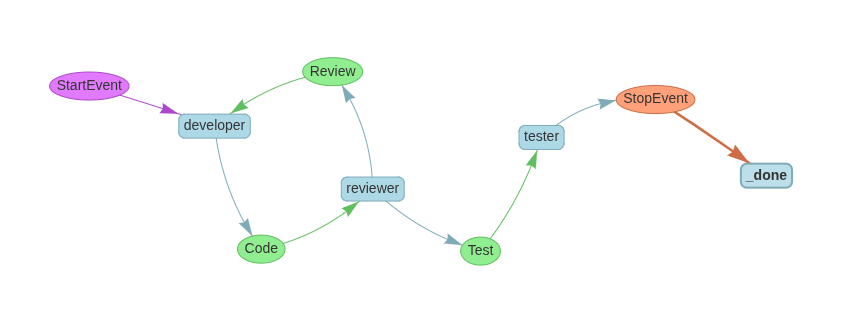
Iterative Feedback Loop (e.g., Code Review Cycles)
Create the event classes to accept and emit by the functions
class AgentLoopWorkflow(Workflow):
def __init__(self,timeout=10, verbose=False):
super().__init__() # call parent class constructor
self.timeout = timeout
self.verbose = verbose
self.iteration_flag = 0
@step
async def developer(self, ev: StartEvent | Review) -> Code:
..........
return Code(code_output="Code changed as per review comments ")
@step
async def reviewer(self, ev: Code ) -> Review | Test:
if self.iteration_flag == 1:
print(ev.code_output)
return Review(review_output="Address the review comments ")
else:
print(ev.code_output)
return Test(test_output="Review completed successfully")
@step
async def tester(self, ev: Test) -> StopEvent:
........................
return StopEvent(result="Test completed successfully")Don’t get perplexed by the interation_flag, it just introduced ti create the review loop.
Depending on the iteration, the loop either continues with feedback or progresses to testing.
Visualization:
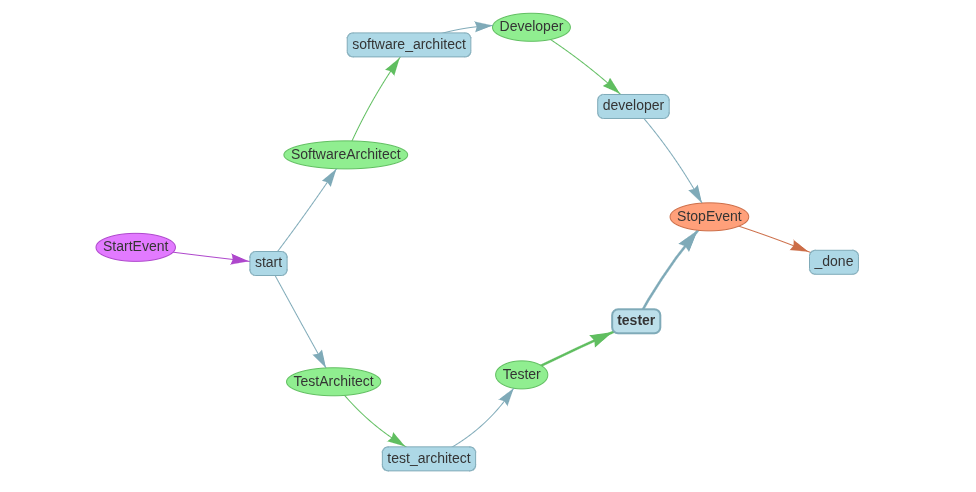
Branching Workflows: Parallel Architect Paths
What if your process starts with either a software architect or test architect?
import random
class AgentBranchWorkflow(Workflow):
@step
async def start(self, ev: StartEvent) -> SoftwareArchitect | TestArchitect:
if condtion:
return SoftwareArchitect(design_output="Software architecture designed")
else:
return TestArchitect(test_plan="Test plan created")
@step
async def software_architect(self, ev: SoftwareArchitect) -> Developer:
return Developer(code_output="Get the Software architecture")
@step
async def developer(self, ev: Developer) -> StopEvent:
return StopEvent(result="Code developed based on architecture")
@step
async def test_architect(self, ev: TestArchitect) -> Tester:
return Tester(test_result="Get the test plan")
@step
async def tester(self, ev: Tester) -> StopEvent:
return StopEvent(result="Testing completed successfully")Visualization:
Parallel Processing with Context.send_event
For concurrent thread-like execution:
import asyncio
class Thread(Event):
query : str
class ParallelWorkflow(Workflow):
@step
async def start(self, ctx: Context, ev: StartEvent) -> Thread:
ctx.send_event(Thread(query="Query for parallel processing 1"))
ctx.send_event(Thread(query="Query for parallel processing 2"))
ctx.send_event(Thread(query="Query for parallel processing 3"))
Workers process them concurrently
@step(num_workers=4)
async def process_thread(self, ctx: Context, ev: Thread) -> StopEvent:
await asyncio.sleep(random.randint(1,5)) # Simulate some processing time
return StopEvent(result=f"Processed thread with query: {ev.query}")Visualization:
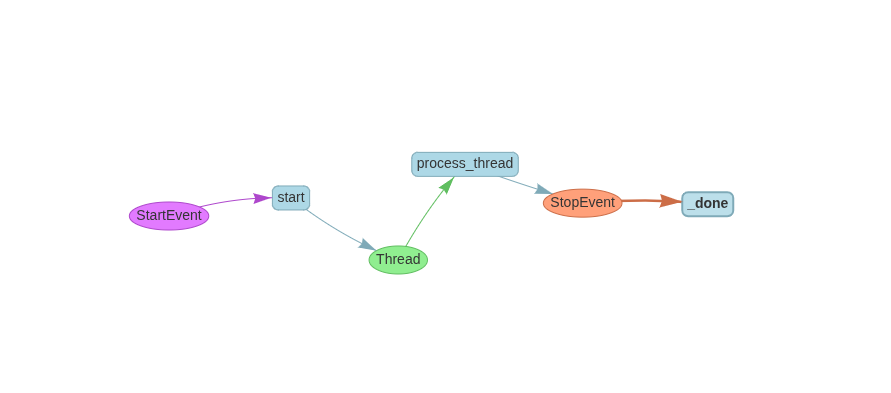
The same can be augmented via ctx.collect to wait for all the events to be received and then ending the workflow.
@step
async def collect_results(self, ctx: Context, ev: CollectorThread) -> StopEvent:
#wait for all events to be collected
result = ctx.collect_events(ev, [CollectorThread] * 3)
if result is None:
print("Not all events collected yet")
return None
print(result)
return StopEvent(result="Done")The collection of parallel output guarantees that the workflow only proceeds once all threads complete.
Concurrent Workflows with Multiple Event Types
Use case: development, testing, and certification occur independently but must finish before delivery.
class ConcurrentWorkflow_DiffEventTypes(Workflow):
@step
async def start(self, ctx: Context, ev: StartEvent) -> Development | Testing| Certification:
ctx.send_event(Development(query="Query for development"))
ctx.send_event(Testing(query="Query for testing"))
ctx.send_event(Certification(query="Query for certification"))
@step
async def process_development(self, ctx: Context, ev: Development) -> DevelopmentComplete:
return DevelopmentComplete(result=ev.query)
@step
async def process_testing(self, ctx: Context, ev: Testing) -> TestingComplete:
return TestingComplete(result=ev.query)
@step
async def process_certification(self, ctx: Context, ev: Certification) -> CertificationComplete:
return CertificationComplete(result=ev.query)
@step
async def Event_Collector(
self,
ctx: Context,
ev: DevelopmentComplete | TestingComplete | CertificationComplete
) -> StopEvent:
events = ctx.collect_events(ev, [CertificationComplete, TestingComplete, DevelopmentComplete])
if events is None:
print("Not all events collected yet")
return None
print("All events collected:", events)
return StopEvent(result="Done")
This showcases dependency resolution across heterogeneous paths and ensure guaranteed and definitive event collection flow based on the sequence described in collect_events irrespective of emission sequence.
Visualization:
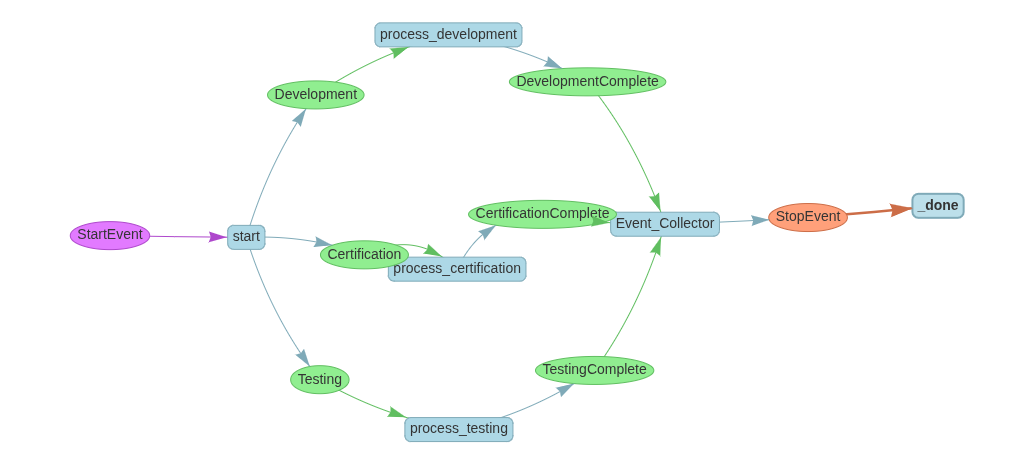
OpenAI Integration: LLM Inside a Workflow
The provided code defines a three-step asynchronous workflow using the llama_index framework, where each step represents a stage in a process.
It begins by signaling progress with a ProgressEvent, then uses OpenAI’s gpt-4o-mini model to stream a response about the Taj Mahal, emitting each token as a TextEvent in real-time.
Finally, it concludes the workflow with a completion message. The workflow supports event streaming, allowing live feedback and progress tracking, making it suitable for interactive or UI-driven applications involving LLMs.
It also helps the user to that LLM is working by giving intermediate response thereby elevating user experience.
class MyWorkflow(Workflow):
@step
async def step_one(self, ctx: Context, ev: StartEvent) -> FirstEvent:
ctx.write_event_to_stream(ProgressEvent(msg="Step one is happening"))
return FirstEvent(first_output="First step complete.")
@step
async def step_two(self, ctx: Context, ev: FirstEvent) -> SecondEvent:
llm = OpenAI(model="gpt-4o-mini", api_key=api_key)
generator = await llm.astream_complete(
"Please give me the first 50 words about Taj Mahal, a monument in India." # Example prompt
)
async for response in generator:
ctx.write_event_to_stream(TextEvent(delta=response.delta))
return SecondEvent(
second_output="Second step complete, full response attached",
response=str(response),
)
@step
async def step_three(self, ctx: Context, ev: SecondEvent) -> StopEvent:
ctx.write_event_to_stream(ProgressEvent(msg="Step three is happening"))
return StopEvent(result="Workflow complete.")workflow = MyWorkflow(timeout=30, verbose=False)
handler = workflow.run(first_input="Start the workflow.")
async for ev in handler.stream_events():
if isinstance(ev, ProgressEvent):
print(ev.msg)
if isinstance(ev, TextEvent):
print(ev.delta, end="")
final_result = await handler
print("Final result = ", final_result)Output:
Step one is happening
The Taj Mahal, located in Agra, India, is an iconic mausoleum built by Mughal Emperor Shah Jahan in memory of his beloved wife, Mumtaz Mahal. Completed in 1653, it showcases exquisite white marble architecture, intricate carvings, and beautiful gardens, symbolizing love and devotion. It is a UNESCO World Heritage Site.Step three is happening
Final result = Workflow complete.This simulates a live LLM-driven response stream during the workflow.
Conclusion
Workflows built with llama_index offer modular, async, and declarative structures to model almost any multi-agent process. Whether you’re creating a dev-test-deploy pipeline or orchestrating LLM interactions, this approach gives you full control and visibility into every step.
Stay tuned for future deep dives on memory integration, agent coordination, and RAG-enhanced workflows!
Links
To get code, check the below jupyter notebook
https://github.com/juggarnautss/Event_Driven_Agent_Doc_Workflow/blob/main/agent_doc_workflow.ipynb: Building Intelligent Agent Workflows with LlamaIndex: From Basics to Advanced Patterns
Author Profile

- AI | Amplifying Impact
- Talks about AI | GenAI | Machine Learning | Cloud | Kubernetes
Latest entries
 AgenticAIAugust 12, 2025Pipeline Companion – an AWS Strands Agent for Data Pipeline Monitoring
AgenticAIAugust 12, 2025Pipeline Companion – an AWS Strands Agent for Data Pipeline Monitoring AgenticAIAugust 7, 2025AWS Strand Agent – integration with Researcher MCP server
AgenticAIAugust 7, 2025AWS Strand Agent – integration with Researcher MCP server AgenticAIAugust 5, 2025Building an MCP Server Using FastMCP and arXiv
AgenticAIAugust 5, 2025Building an MCP Server Using FastMCP and arXiv AgenticAIAugust 3, 2025Building a Resume Question-Answering System Using LlamaIndex, OpenAI, and LlamaParse
AgenticAIAugust 3, 2025Building a Resume Question-Answering System Using LlamaIndex, OpenAI, and LlamaParse