
As per Wiki definition, “iptables is a user-space utility program that allows a system administrator to configure the IP packet filter rules of the Linux kernel firewall, implemented as different Netfilter modules”.
In simple words, iptables is linux basic firewall software. Just like a mini version of firewall , it does packet filtering whether to allows, blocks or forward packets.
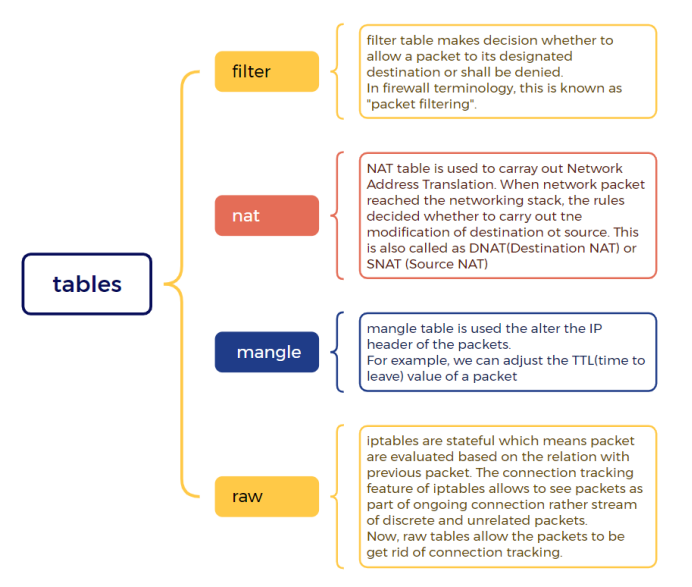
- Iptables contains multiple tables to manage the rules. Based on the type of rules and its applicability , user has to create and add rules to a particular table to make the rules work correctly. For example, if a rule is required for network translation, it will be put in nat table. If the rules is to allow or to discard packets , then it will be put in filter table.
- Inside each iptables table, rules are further organized into separate chains. Chains are mapped to kernel netfilters hooks which decide when the rules will be triggers. We can have a single chain or cascading chains based of requirement. A chain can be empty also.
- At the end, we have rules which are the last mile resource, which decides the fate of the packets. Rules can accept, block, forward packets. Rules can accept, block, forward packets coming from certain subnets, for a particular port etc. The outcome of a rule is called Policy. The policy decides whether to drop, accept or reject the traffic.
Successor of iptables is nftables, in modern day system, it has been seen that nftables are getting used, however still iptables are used in the background in order to support legacy network softwares.
Iptables table and their applicable chains:
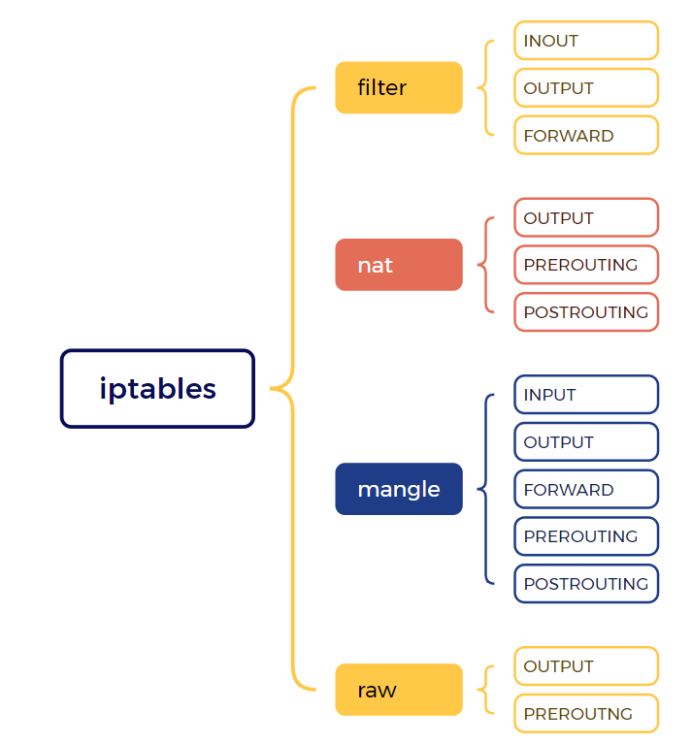
Tables and their usage:
Built-in Chains (default chains provided by Netfilter):

Demo:
As we understood the theory and concepts of iptables, lets get our hand dirty.
In this demo, we will deploy simple Kubernetes application with two replicas and exposed it using a NodePort service. After then we will analyze iptables rules to uncover how Kubernetes routes and load-balances traffic at the network level.
Filename: hello-app-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-app
spec:
replicas: 2
selector:
matchLabels:
app: hello-app
template:
metadata:
labels:
app: hello-app
spec:
containers:
- name: hello-app
image: gcr.io/google-samples/hello-app:1.0
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: hello-app-service
spec:
type: NodePort
selector:
app: hello-app
ports:
- protocol: TCP
port: 80
targetPort: 8080host1$kubectl apply -f hello-app-deployment.yaml
host1$kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-app-service NodePort 10.104.81.240 <none> 80:30811/TCP 2m57s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 20d
host1$kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hello-app-58d97c88d4-h7s2n 1/1 Running 0 3m14s 172.16.166.130 host1 <none> <none>
hello-app-58d97c88d4-pkh8c 1/1 Running 0 3m14s 172.16.192.89 host2 <none> <none>Observation: We can see that after the deployment, we have 2 pods running. In services, apart from NodePort, note that ClusterIP service is assigned by default.
Now suppose, a user fires a curl command “curl http://<NodeIP>:30811”. Lets trace how this command will reach the end mile resource ie pods behind the NodePort service with the help of iptables.
Lets check the iptables rules.
host1$sudo iptables -n -t nat -L KUBE-SERVICES
Chain KUBE-SERVICES (2 references)
target prot opt source destination
KUBE-SVC-NGVTFAARHANBXKRK tcp -- 0.0.0.0/0 10.104.148.121 /*
KUBE-SVC-YG6ZEOBCLVGD3AJB tcp -- 0.0.0.0/0 10.104.81.240 /* default/hello-app-service cluster IP */
KUBE-NODEPORTS all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCALObservation: In NAT table, KUBE-SVC-XXXX chain handles that any incoming tcp traffic or curl request coming from any source will get directed to NodePort IP ie 10.104.81.240. Internally KUBE-SVC-XXXX chain does the load balancing means direct the traffic to one of the 2 pods managed by the service. Lets see how ?
host1$sudo iptables -n -t nat -L KUBE-SVC-YG6ZEOBCLVGD3AJB
Chain KUBE-SVC-YG6ZEOBCLVGD3AJB (2 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- !172.16.0.0/16 10.104.81.240 /* default/hello-app-service cluster IP */
KUBE-SEP-7I3URQ2O437FVP5U all -- 0.0.0.0/0 0.0.0.0/0 /* default/hello-app-service -> 172.16.166.130:8080 */ statistic mode random probability 0.50000000000
KUBE-SEP-PSPHHDAXPY5YRT7B all -- 0.0.0.0/0 0.0.0.0/0 /* default/hello-app-service -> 172.16.192.89:8080 */Observation: In NAT table, deep dive inside KUBE-SVC-YG6ZEOBCLVGD3AJB chain reveals that service will load balance the request between two pods randomly with 0.5 % probability.
host1$sudo iptables -n -t nat -L KUBE-SEP-PSPHHDAXPY5YRT7B
Chain KUBE-SEP-PSPHHDAXPY5YRT7B (1 references)
target prot opt source destination
KUBE-MARK-MASQ all -- 172.16.192.89 0.0.0.0/0 /* default/hello-app-service */
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/hello-app-service */ tcp to:172.16.192.89:8080Observation: Ultimately the leaf chain where the request is landing ie one of the pod IP.
By breaking down the iptables rules, we’ve gained basic insights of Kubernetes cluster networking uncovering how traffic seamlessly flows from external users to application pods.
In this article, we have covered “iptables” tables dealing with ipv4 traffic, however same concept applies to “ip6tables” for ipv6 traffic.
In next article, we will be covering Kubernetes services focusing on the networking aspects.
Good Bye for now. Stay tuned.
References:
https://en.wikipedia.org/wiki/Iptables
https://man7.org/linux/man-pages/man8/iptables.8.html
Author Profile

- AI | Amplifying Impact
- Talks about AI | GenAI | Machine Learning | Cloud | Kubernetes
Latest entries
 AgenticAIAugust 12, 2025Pipeline Companion – an AWS Strands Agent for Data Pipeline Monitoring
AgenticAIAugust 12, 2025Pipeline Companion – an AWS Strands Agent for Data Pipeline Monitoring AgenticAIAugust 7, 2025AWS Strand Agent – integration with Researcher MCP server
AgenticAIAugust 7, 2025AWS Strand Agent – integration with Researcher MCP server AgenticAIAugust 5, 2025Building an MCP Server Using FastMCP and arXiv
AgenticAIAugust 5, 2025Building an MCP Server Using FastMCP and arXiv AgenticAIAugust 3, 2025Building a Resume Question-Answering System Using LlamaIndex, OpenAI, and LlamaParse
AgenticAIAugust 3, 2025Building a Resume Question-Answering System Using LlamaIndex, OpenAI, and LlamaParse