Problem Statement
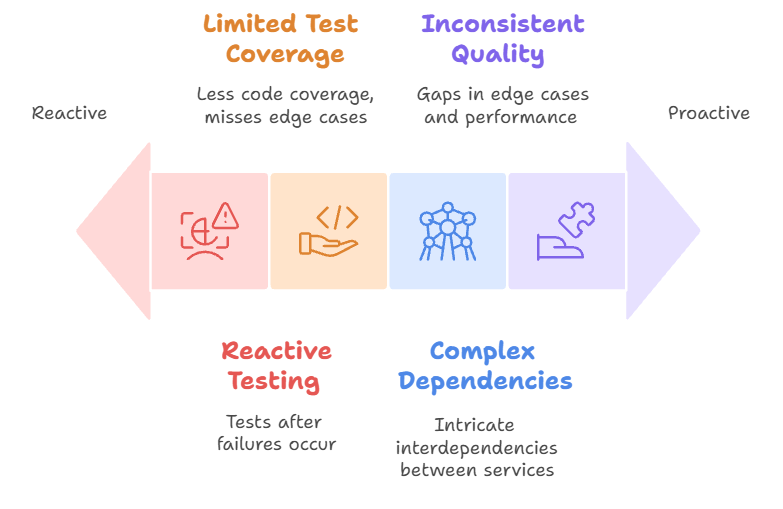
Modern data pipelines are built on AWS services such as Glue, Lambda, Step Functions. Testing these pipelines—especially under schema change, scale, and integration demands—is a major bottleneck.
Manual testing is slow, prone to oversight, and unable to adapt to dynamic, distributed pipeline environments.
Data pipeline failures in production environments cost organizations time, money and schedule.
More important, debugging and troubleshooting pipeline failures gives engineer a stressed and hectic time.
Survey Insights wrt Scale of the Problem:
- $3.1 trillion in annual losses globally due to poor data quality (IBM, 2023)
- Average downtime cost of $5,600 per minute for data-dependent applications
- Manual testing overhead consuming 40-60% of data engineering resources
Core Challenges and Issues
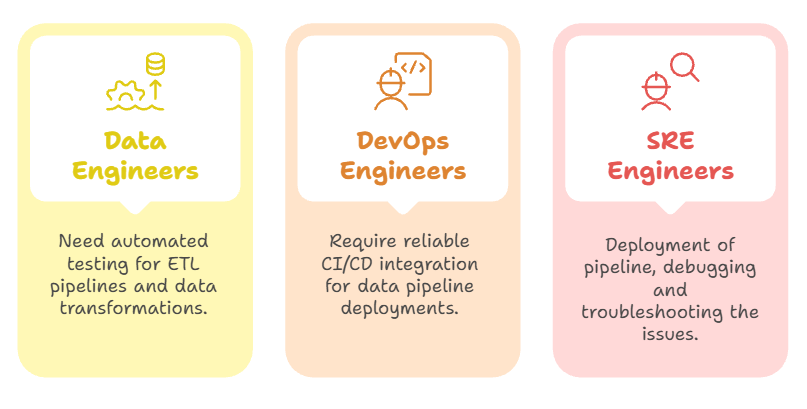
Target User
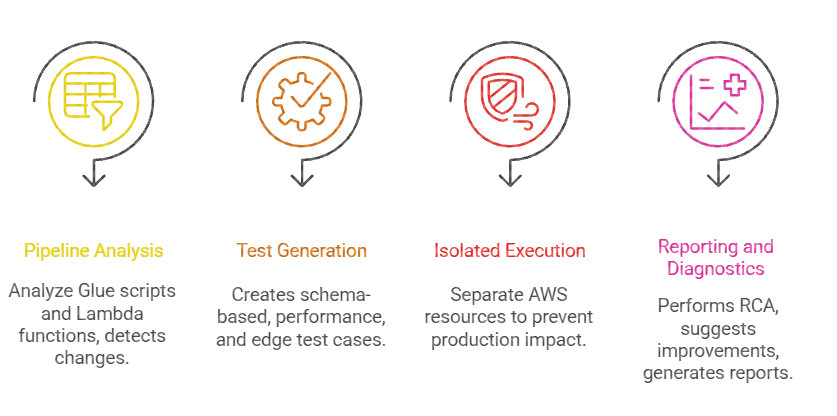
Solution and Technical Components
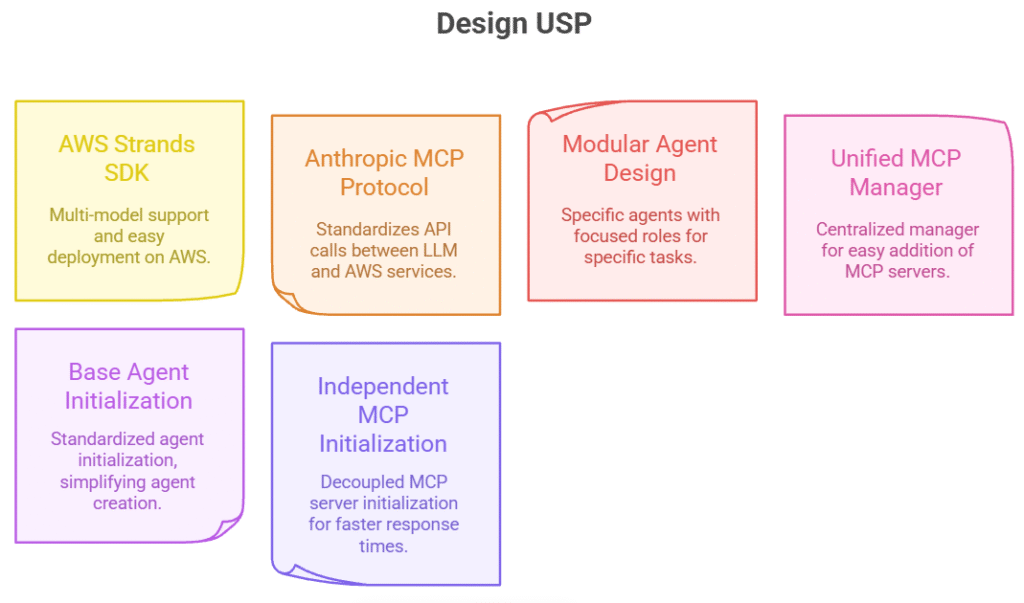
Pipeline Companion is an AI-powered autonomous testing framework that redesigns how organizations test and validate AWS data pipelines. Integrating Model Context Protocol with agents, it automatically understands pipeline logic, generates comprehensive test scenarios, executes tests in isolated environments, and provides diagnostics.
Features of Pipeline companion
Architecture
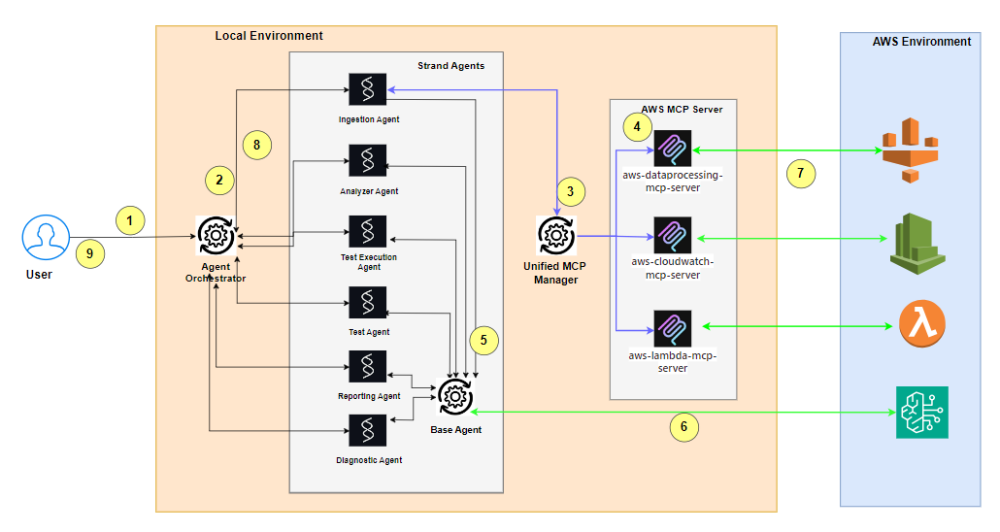
Flow of a typical event:

Agent Development
Github: https://github.com/juggarnautss/Pipeline_Agent
Here’s a code skeleton and explanation:
main.py: Entry point. Initializes the orchestrator and starts CLI/web/demo modes.
# ...existing code...
from agents.orchestrator import AgentOrchestrator
def main():
companion = AgentOrchestrator()
# CLI or web entry point
# Example: companion.chat("Analyze my Glue job called data-processor")
# ...existing code...
orchestrator.py: Central router. Decides which specialized agent(s) handle each user request.
# ...existing code...
class AgentOrchestrator:
def __init__(self):
self.analyzer = AnalyzerAgent()
self.tester = TestAgent()
self.diagnostician = DiagnosticAgent()
self.reporter = ReportingAgent()
self.test_executor = TestExecutionAgent()
def process_user_request(self, user_prompt: str) -> str:
# Route request to appropriate agent(s)
pass
def chat(self, message: str) -> str:
return self.process_user_request(message)
# ...existing code...base_agent.py: Abstract base for all agents. Handles model setup, MCP integration, and tool management.
# ...existing code...
class BaseAgent(ABC):
def __init__(self):
self.model = BedrockModel(...)
self.mcp_manager = get_unified_mcp_manager()
self.mcp_status = self.mcp_manager.get_server_status()
@abstractmethod
def get_tools(self):
pass
@abstractmethod
def get_system_prompt(self) -> str:
pass
def process(self, message: str) -> str:
agent = Agent(
model=self.model,
tools=self.get_agent_tools(),
system_prompt=self.get_enhanced_system_prompt()
)
result = agent(message)
return result.message if hasattr(result, 'message') else str(result)
# ...existing code...analyzer_agent.py: Example specialized agent. Implements analysis tools and prompts.
# ...existing code...
class AnalyzerAgent(BaseAgent):
def get_tools(self):
# Return analysis tools and MCP tools
pass
def get_system_prompt(self) -> str:
# Return prompt for analysis tasks
pass
@tool
def _analyze_pipeline_health(self, health_request: Dict[str, Any]) -> str:
# Health check logic
pass
# ...existing code...unified_mcp_manager.py: Manages connections to AWS MCP servers (Glue, Lambda, CloudWatch) for deep pipeline insights.
# ...existing code...
class UnifiedMCPManager:
def __init__(self):
self.cloudwatch = CloudWatchMCPServer()
self.glue = GlueMCPServer()
self.lambda_server = LambdaMCPServer()
self._initialize_servers()
def get_server_status(self) -> Dict[str, Any]:
# Return status of MCP servers
pass
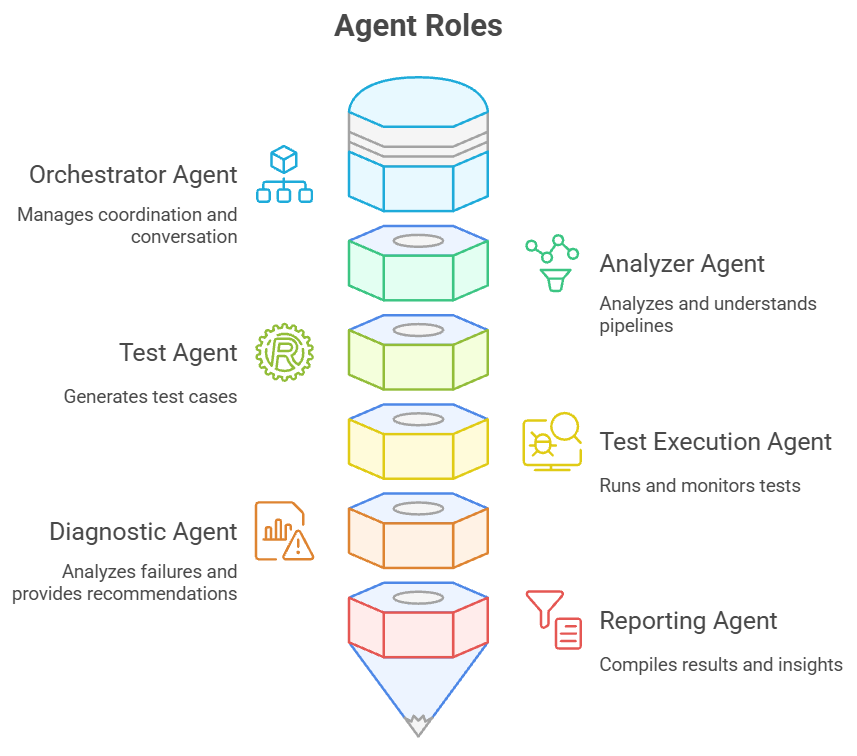
# ...existing code...Each agent (Analyzer, Tester, Diagnostic, Reporting, Test Execution) inherits from BaseAgent and provides domain-specific tools and prompts. The orchestrator coordinates single or multi-agent workflows based on user intent.
User Interface
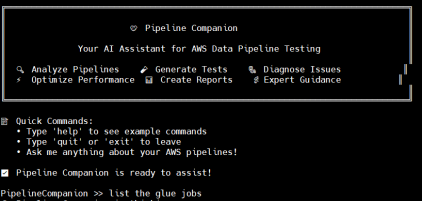
Command Line Interface:
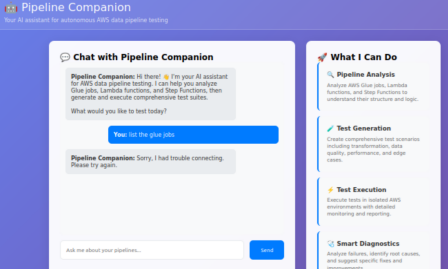
GUI:
Deployment
| Local deployment | Using uv package manager we can install the all packages via requirement file. Create a python virtual environment Export the AWS configuration Run the main using python3 |
| Amazon EC2 | Use TypeScript CDK to deploy the agent to EC2. Once deployed, you can test your agent using the public IP address and port. |
| Amazon EKS | Prerequisite is to containerized the Pipeline companion agent using docker. The deploy the pipeline companion suing helm charts in EKS Use ALB to route the traffic to EKSAccess the pipeline companion using ALB DNS name |
| Lambda and Fargate | As per AWS strands documentation |
Conclusion
Pipeline Companion demonstrates the power of agentic AI in automating and enhancing AWS data pipeline testing. By leveraging specialized agents and deep AWS integration, it delivers rapid, reliable analysis, intelligent test generation, and actionable diagnostics.
This approach not only accelerates development cycles but also improves pipeline resilience and data quality. As agentic frameworks evolve, solutions like Pipeline Companion will become essential tools for modern data engineering teams seeking scalable, autonomous pipeline validation.
References
Author Profile

- AI | Amplifying Impact
- Talks about AI | GenAI | Machine Learning | Cloud | Kubernetes
Latest entries
 AgenticAIAugust 12, 2025Pipeline Companion – an AWS Strands Agent for Data Pipeline Monitoring
AgenticAIAugust 12, 2025Pipeline Companion – an AWS Strands Agent for Data Pipeline Monitoring AgenticAIAugust 7, 2025AWS Strand Agent – integration with Researcher MCP server
AgenticAIAugust 7, 2025AWS Strand Agent – integration with Researcher MCP server AgenticAIAugust 5, 2025Building an MCP Server Using FastMCP and arXiv
AgenticAIAugust 5, 2025Building an MCP Server Using FastMCP and arXiv AgenticAIAugust 3, 2025Building a Resume Question-Answering System Using LlamaIndex, OpenAI, and LlamaParse
AgenticAIAugust 3, 2025Building a Resume Question-Answering System Using LlamaIndex, OpenAI, and LlamaParse